Visualizing Text Embeddings
Visualizing text embeddings in two dimensions, on the web.
Loading... (JavaScript required)
I recently watched But what is a GPT? Visual intro to transformers, by 3Blue1Brown. This video (and the next one in this series) is a very good explainer of transformers and GPT. I highly recommend that you watch it.
In the video, there's a part where he's explaining word embeddings. A word embedding is a representation of a word encoded as a vector in a high-dimensional space. Directions in this space can encode semantic meaning.
For example, consider the words "man" and "woman". The difference between the embeddings of these two words are comparable to the differences between "king" and "queen".
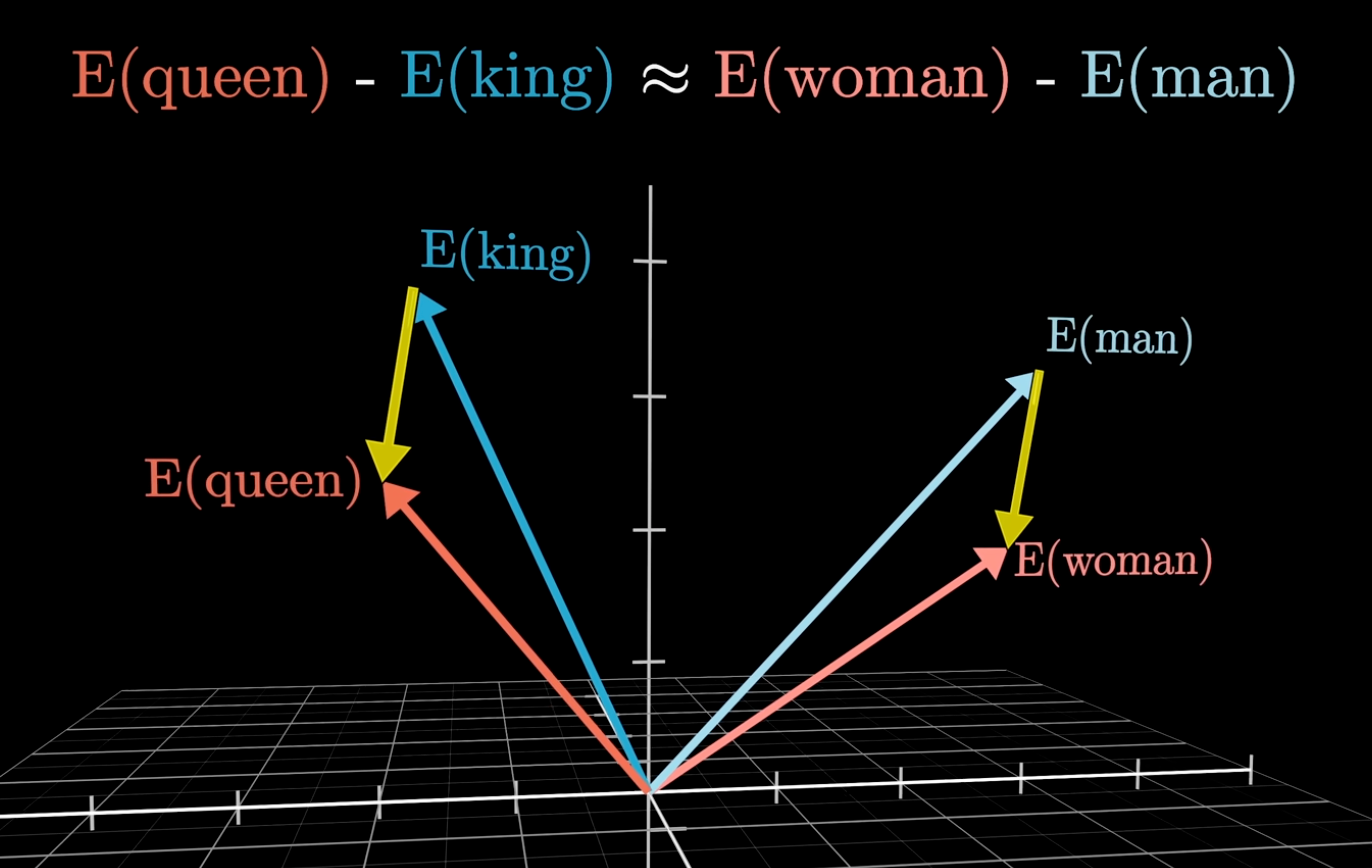
It's not exactly the point of the video, but my first thought when I watched this part is, "I want to play around with it".
He did share the source code of the program he used to generate those animations, but it's written in Python, and you have to download and install a bunch of stuff. I thought it would be interesting to implement it as a web app, so anyone can quickly use it.
Also, it's a good excuse to try out the latest AI tools for the web.
Generating the Embeddings
The original video uses GloVe to produce the embeddings. However, GloVe is distributed as a lookup table of words to vectors, so the size scales with the amount of words. Also, I'll only be able to get the embedding of single words with it.
Instead, I'll use Supabase/bge-small-en, which is a transformer embedding model with only 34MB weights. To run it, I used transformers.js, which is designed to be equivalent to the commonly used transformers Python library.
Conveniently, Supabase has converted this model to be easily runnable in a browser. They even provided a code sample to run it in the browser. Modern transformer libraries are very easy to use, so this is actually the easiest part of this project.
import { pipeline } from '@xenova/transformers';
const pipe = await pipeline(
'feature-extraction',
'Supabase/bge-small-en',
);
const output = await pipe('Hello world', {
pooling: 'mean',
normalize: true,
});
const embedding = Array.from(output.data);
console.log(embedding); // And that's it!Displaying in two Dimensions
After generating the embeddings, we need to display the vectors on the screen. The embedding vectors are in a high-dimensional space. Even this bge-small-en model produces a 384 element vector. We'll have to somehow reduce this to only two dimensions.
To do this, we can use Principal Component Analysis. It will find the directions in an n-dimensional space that has the most variance among a dataset. To visualize the dataset, we can just take the two topmost directions and use it as the x and y axis respectively.
Since the directions are based on the data, when the data changes, the direction with the most variance will also change. This can put the same vectors in completely different places based on what the other vectors are. In the tool above, I added an option to pause updating the projection, so new words or changes will not affect the other words.
I used an implementation provided by the mljs organization in GitHub. They also provide other machine learning tools that can be used in a browser. It's a good reminder that even though LLMs currently draw a lot of interest, there are other machine learning tools that might be more suitable for your problem.
Download Size
One problem with building this tool is the download size of the models. Compared to almost any other library, it's huge. The PCA implementation I used is only around 3kb gzipped. Even something like Google Docs will only need you to download 10MB of data. The model I used is 34 MB.
As of this writing, the global median internet speeds are around 50 Mbps for mobile and 90 Mbps on fixed broadband. That means there's at least a few seconds that the user needs to wait until the model is downloaded. Having a progress indicator for this is crucial. If your app looks stuck, the user might just abandon it.
Of course, there will be users with internet speeds slower than that. I actually tested this page with my phone set to only use 4G, and the download speeds dropped to around 10-15Mbps. I had to stare at my screen for 20 seconds before it finishes loading. I don't expect anyone else will be willing to wait that long.
To avoid downloading the model on page load, I stored the embedding values of all the words I used in this page, and only download the model once the user edits something in the tool. Most of the demos I tried from the transformers.js repo use a similar pattern. They only download the models when it's actually needed.
Thankfully, the library will automatically cache the model once it's completed, so at least you only need to finish the download once.
The Results
After playing around with this tool a bit, I have to admit, the visualizations are not that interesting 😂
Although some sets of sentences produce interesting patterns, there's a lot that doesn't. The examples that you saw in this article are the best ones that I found.
The more interesting part to me is building it, particularly how easy it is. When I first got this idea, I expected I would at least have to figure out how to convert the models to web format, find a compatible library based on the models, host the files, etc. But nope, the AI part is barely ten lines of code.
There are a lot of other interesting models supported by transformers.js. I might try them out to build other things later.